上周末和北京胡同客栈的左岸,“一人”去十三陵徒步,把每个陵都走了个遍。 不多说了,上图。
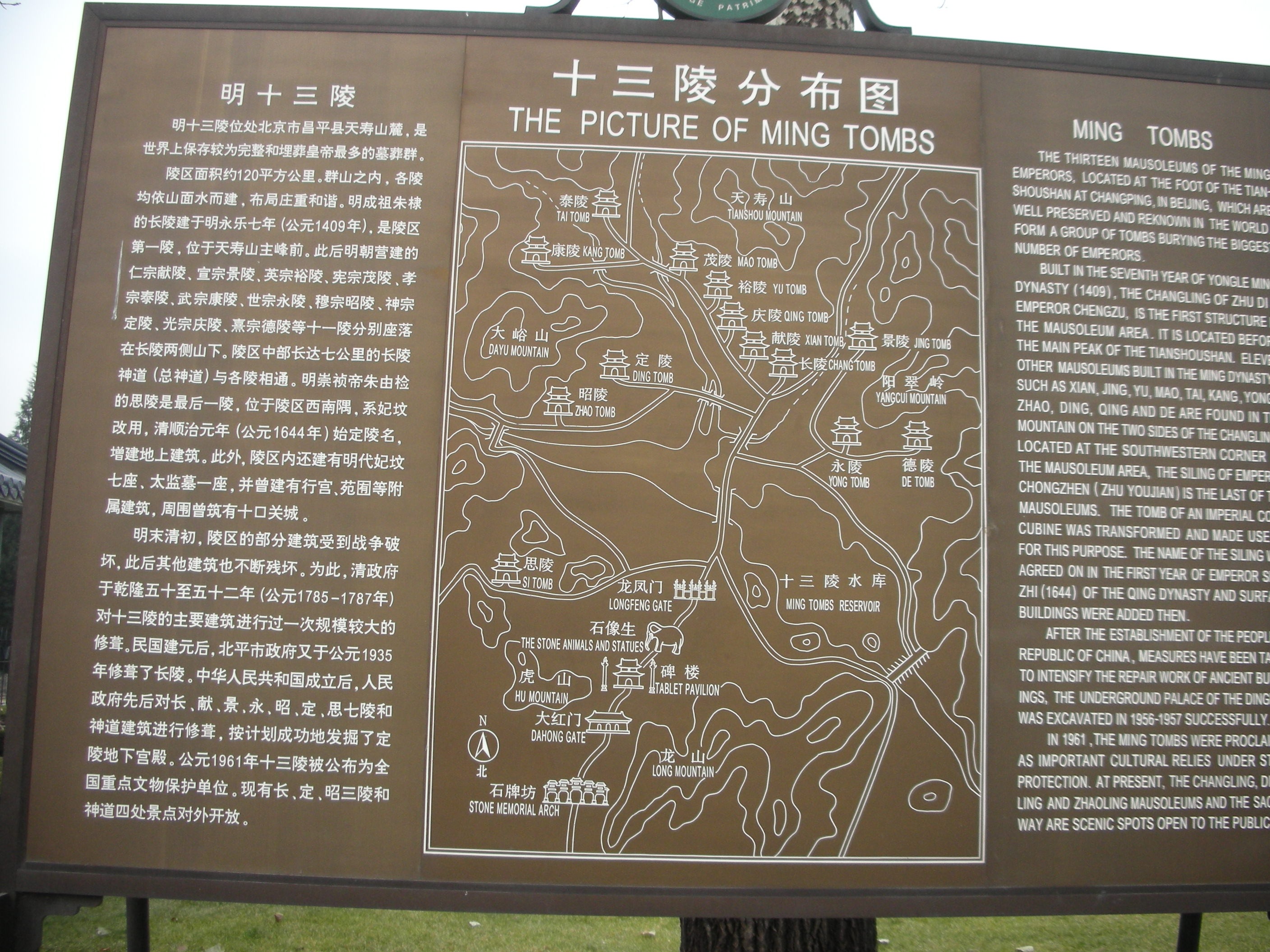
十三陵地图 (图片点击后可看到原始大图)。明朝有16个皇帝,但只有13个陵。因为朱元璋葬在南京明孝陵,靖难之变后建文帝生死不知,没有建陵。而土木堡之变后上台的景泰帝朱祁钰,被他哥哥英宗成功复辟,剥夺了皇帝的身份,没能葬入皇陵。
神道地图 (点击可看大图)。神道是长陵的入口。长陵是埋葬成祖朱棣和皇后徐氏的,是十三陵的第一个陵,算是十三陵中的祖陵,在十三陵中规模最大。神道到长陵还有几公里的距离。其他的陵规模都要比长陵小。这是因为朱棣的儿子仁宗朱高炽去世前要求自己的陵墓俭约,为以后的明皇陵寝定下了俭约的基调。

神功圣德碑。

前面就是神道了,能依稀见到远处两侧石像。
二十多年前我们全家来过一次十三陵,妹妹当时还骑在这个骆驼上照了张像。冬去春来二十多载,骆驼没啥变化,妹妹已经从可爱的瓷娃娃变成了体育营销专家。

回望神道

离开了神道后徒步了1个多小时,终于到了永陵的红墙边,照片中央繁密的松柏下就是埋葬明朝第十一位皇帝世宗朱厚熜(嘉靖)及陈氏、方氏、杜氏三位皇后的坟丘。嘉靖在位时热衷炼丹修仙,盼望着得道升天,可修来修去还是修到了地底下。

永陵的大门,都锁着。

从门缝里拍。这里要赞一下Windows live writer, 本来这个照片在acdsee上看是躺着的,想插入后加个旋转的特效。没想到live writer自动旋转了90度。

永陵旁边就是德陵了,过了桥就是。 十三陵大都靠山依水,应该是为了风水。后面看到的陵大多门前有桥,不过河床都干涸了。德陵埋葬着明朝第十五位皇帝熹宗朱由校和皇后张氏。提起熹宗可能有些人不清楚是谁,要说他是那个宠信魏忠贤的皇帝大家应该有印象吧。

德陵的门和永陵不同,不是砖石结构,而是木结构。 这是因为熹宗酷爱木工么? 后来发现用木头做大门的不只德陵。

从门缝里看到的德陵内部。

我们绕着德陵转了一圈,围着坟丘的砖石看着很新,贴近看,发现有的砖有“公元二00二”的字样,看来是新整修的。

从下面照片里可以看到陵内依然是保存着旧砖,用钢筋加固。在这里我们遇到一个山林守护的老者,他说每个陵都有守陵人,平常很少出来;原先守陵的都是些老人,前两年都换成年轻人了……………………五十多岁的(狂晕)。退休的守陵人大约都在七十多岁。老者进过周围的几个陵,他说德陵让人感觉阴森,而永陵则比较敞亮。

看完德陵我们又超近路回到永陵的后边,看到树木已经拱破了坟丘的护墙。如果不加人为干涉,没准再过几百年,又是一个Ta pron。

在一块砖上有嘉靖年间的标示。

在一块砖上还有制作人的名讳。

吃完午饭去了景陵,铁将军把门。景陵埋葬着明朝第五位皇帝宣宗朱瞻基与皇后孙氏。绕着陵转了转,发现景陵内的松柏,颇多呈现枯黄,不似永陵和德陵的林木繁茂。后来查到一些资料,说他有弑父的嫌疑,这和树木的枯黄有关系么?

去了长陵,这是最早开放旅游的陵之一,也是十三陵中规模最大的,游人很多。这里埋葬着明朝第三位皇帝成祖朱棣和皇后徐氏。朱棣的故事在明朝的那些事儿中有大篇幅的介绍,写得非常精彩,推荐大家读读。

下面的几个陵都非常好找,以长陵打头阵,排着一个长队,向西北方向延伸开去。这个队伍的第二个陵就是献陵,埋葬着明朝第四位皇帝仁宗朱高炽和皇后张氏。从大门就可看出,献陵确实是如他所愿的俭约。朱高炽在位时间很短,不到一年,但他开启了明朝的”仁宣之治”,很多人对他评价很高。

庆陵,埋葬着明朝第十四位皇帝光宗朱常洛和皇后郭氏、王氏、刘氏。大门已经完全没有了,只有门旁的砖墙还能让人依稀看出大门的规模。不过祾恩殿(就是照片中间最高的那个楼)看着保存的还不错。整个陵看着比较破败,但已经知道这还不是最破败,因为我们已经遥遥望见了裕陵和茂陵。

裕陵,埋葬着明朝第六位皇帝英宗朱祁镇和皇后钱氏,周氏,就是土木堡之变中被人绑架,被弟弟取而代之的那位,后来又造了弟弟的反,拿回了皇位。

绕着裕陵走了一圈,看到了破败的围墙。从裸露出的砖石来看,感觉这个陵建得比较潦草。



下面是十三陵中最破的茂陵,埋葬着明朝第八位皇帝宪宗朱见深和王氏、纪氏、邵氏三位皇后。茂陵的祾恩殿远处看去比裕陵的还要破败的多,摇摇欲坠的感觉。近了因为树木挡着,反倒看不真切了。

在去泰陵的路上居然看到打铁的,本以为这个行业早就绝迹了的。他们正在打农具。

泰陵,当时天快黑了,已经看不太清。这里埋葬着第九位皇帝孝宗朱佑樘及皇后张氏。泰陵在建好后很多人说此地的风水并不好。孝宗开创了弘治中兴,算是一个好皇帝。从他去世后明朝皇帝就一茬不如一茬,不知道是不是因为泰陵的风水不佳。

到康陵的时候已经完全黑下来,只好在旁边的康陵村先住下来,第二天早晨再去看。康陵埋葬着明朝第十位皇帝武宗朱厚照和皇后夏氏,这个武宗就是《游龙戏凤》的主角。有人说他荒淫无耻,也有人说他追求人性解放。

定陵,埋葬着第十三帝朱翊钧(就是万历)和他两个皇后。二十多年前来过这里,还下到了地宫,不过记忆都模糊了,只是感觉这大门似乎比20年前更新。这是十三陵中唯一开挖了地宫的陵。

昭陵,埋葬着第十二位皇帝穆宗朱载垕及其三位皇后。这个皇帝在位6年从未公开发表过自己的政治主张。十三陵中只有它和长陵,定陵对游客开放, 其他十个游人都不能进。

思陵是我们用了最长时间去寻找的一个陵,位置比较偏,甚至有当地人都不知道这个陵的确切所在。这里埋葬着明朝最后一帝崇祯帝朱由检及皇后周氏、皇贵妃田氏。思陵是明朝亡国后,由清朝在顺治年间修建的,陵寝的规模与前十二个完全不能相比。本来这只是皇贵妃田氏的墓,后来把崇祯改葬到这里,并加以扩建成为帝陵。在建思陵的时候,明朝旧臣捐了一些钱,其中吴三桂捐了千两。思陵在清朝灭亡后被盗挖过两次,里面保存的古迹已经很少,连祾恩殿都看不到,不知道是不是当初就没有建。还有个和其它十二陵不同的是,陵前的功德碑不是由龟驮着的,而是就放在石头上。在清朝,不少汉族文人不承认思陵是个皇陵。

十三陵中的前十二陵在每个陵旁边都有以这个陵命名的村子,比如长陵村,永陵村之类,只有思陵旁边的村子没有以思陵命名,而是叫悼陵涧。
疑问:为什么古埃及和中国有厚葬的传统,而欧洲没有呢?(亦或是我孤陋寡闻没有听说?)
参考资料:http://baike.baidu.com/view/8341.htm