在google中搜索”LogFormat“发现了第二个结果旁边有下面用红框标志的东西, 很好奇. 我看到的时候VIsit还是2, 时间几十分钟前的时间, 等我用打开了那个搜索结果后, 再刷新搜索页面, Visit就变成了3, 时间也变成了我打开那个搜索结果的时间. 当logout google account以后, 这个统计消失. 看来显示的是我这个google账号访问搜索结果的统计.

在另一台机器上, 用另一个google账号登陆, 访问中文google没看到这个功能
在google中搜索”LogFormat“发现了第二个结果旁边有下面用红框标志的东西, 很好奇. 我看到的时候VIsit还是2, 时间几十分钟前的时间, 等我用打开了那个搜索结果后, 再刷新搜索页面, Visit就变成了3, 时间也变成了我打开那个搜索结果的时间. 当logout google account以后, 这个统计消失. 看来显示的是我这个google账号访问搜索结果的统计.
在另一台机器上, 用另一个google账号登陆, 访问中文google没看到这个功能
在linux下读一个巨大的日志文件, 2.4G
用正文文件的方式打开, 一行一行的读
char achbuf[ 4096 ] ; ifstream ifile( "/cygdrive/h/logs/zz/ex051117.log" ) ; if ( !ifile ) { cout << "error in opening" << endl ; return -1 ; } int i ; for( i = 0 ; !ifile.eof() ; i++ ) { ifile.getline( achbuf , sizeof( achbuf ) - 1 ) ; }
这个过程用了51秒
2.4G的文件用51秒, 47M每秒, 已经接近硬盘的最高速度了.
当时想做个尝试, 看看用二进制方式打开一次读入16M能否会更快.
char achbuf[ 4096 * 4096 ] ; ifstream ifile( "file.log" , ios::in | ios::binary ) ; if ( !ifile ) { cout << "error in opening" << endl ; return -1 ; } int i ; for( i = 0 ; !ifile.eof() ; i++ ) { ifile.read( achbuf , sizeof( achbuf ) ) ; }
这个过程竟然用了96秒!!!!!!!!!!
到论坛请教了一下, co给出一个链接: Fast read of binary files that alternate type
试了试co推荐的文章里说的方法, 加了 ifile.imbue( std::locale::classic());, 结果为88秒, 有提高.
改用下面的代码读是54秒, 和第一个速度相近了
FILE *pfile ; pfile = fopen( "file.log" , "rbS" ) ; if ( pfile == NULL ) { cout << "error in opening" << endl ; return -1 ; } int i ; for( i = 0 ; !feof( pfile ) ; i++ ) { fread( achbuf, 1 , sizeof( achbuf ) , pfile ) ; //16M } fclose( pfile ) ;
刚开始学习stl,不太清楚stl文件io实现的内部机制, 不清楚为什么二进制和正文文件的读入速度差这么多.
有知道的请不吝赐教. 有能答疑解惑者,赠烤鸭一只
现在是凌晨4点45, 坐在窗口旁, 俯瞰着整个小区。路灯静静得亮着,远方的工地偶尔传来一些机械的声音,旁边闷闷的电脑风扇声。又一个中秋开始了。
测试用Writely 来写blog ,感觉不错。在线Office 2007的测试帐号没申请到,只好先用用google。已经越来越喜欢上google的线上软件,微软做的能有这么好么?
update: Writely写的blog还是有些问题, 标题是空的,更新后又生成一个新的post. 看来还是要先用微软的Live writer
http://www.searchmash.com 悄无声息的发布了,有一些有趣的新特性。用户可以移动搜索结果,搜索文字会同时搜索图像,搜索结果中暂时没有Adwords广告。 mash是麦芽汁的意思,但google发布这个搜索引擎是什么意思却让人琢磨不透。难道是为了试验由用户主动参与来改进搜索结果? 还是以后google一些新的搜索技术会先在这个引擎尝试?
版本6.06。 下面是浏览新浪网的截图:
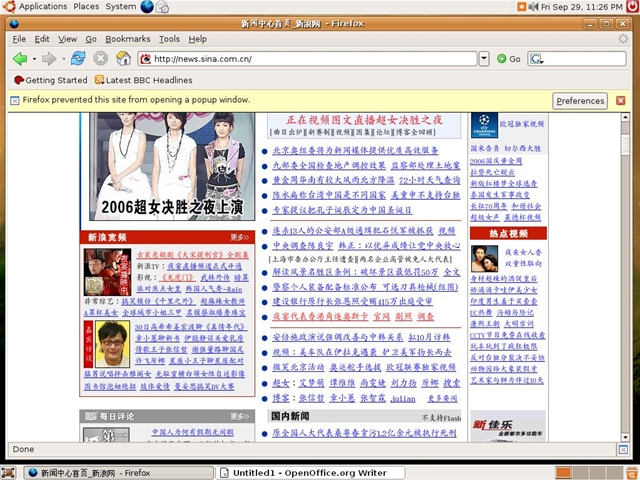
效果不错, 就是中文字体不太好, 应该可以靠下载字体解决。安装过程非常简单,不比前几天安的Vista复杂. 随机安的软件里有OpenOffice, 浏览器Firefox, 还有Gaim Messenger, Evolution Email, Softphone, 多媒体播放器,居然还支持Remote Desktop, 绝对够用了. 据说Suse Linux的桌面比它的更酷,还没看过。2000年的Gnome就已经很漂亮, 但当时的配套桌面软件还不是那么成熟,现在感觉已经是完全可以和 Windows一角短长了。
将来Linux会不会在桌面市场替代Windows呢? 太古老的话题,可总是吸引人们讨论下去。 我现在用的软件有两个趋势, 一个是越来越多用Web的软件, 比如RSS Reader用Google Reader; Email 虽然还是用Outlook处理,但越来越多的用gmail; One note很少用了, 而是用google 的notebook, 家里记账原先用excel, 现在用google spreadsheet. 另一个趋势就是用开源的软件越来越多, 设计数据库用DB Designer, Text Editor用notepad++, 开发Linux下的C++程序用Eclipse, 记日记用Wordpress。 昨晚仔细看了看Vista, 说实话, 相当让我失望。 感觉并没有什么特别吸引人的特性。当初DOS到Windows 3.0, Windows3.1到Windows 95, Windows 95到98, 到2000都还是有特别吸引我的地方,让我迫不及待的升级。从2000到XP这个积极性就下降了很多, 到了Vista没带给我任何想升级的冲动。不知道是不是真的老了,还是Vista真的让人失望。
如果说Windows 和Linux是IT世界的两极,我好像越来越偏向Linux了。
今天在Google Reader上看到有人推荐
Google Sitemaps – UTW Tag Addon for WordPress 2.0, 感觉想法不错, 应该对SEO有帮助, 按照那个网站上说的步骤装了一个。 结果看输出的sitemap.xml 居然里面的tag 链接都是指向这个插件作者的站点。 看了他的php源码, 居然把自己站点的链接写死在了代码里。 改成自己的试了试, 发现还是不行, 才注意到他在URL中没有考虑到亚洲字符。 自己也能改, 但不想浪费时间直接给卸载了。
大家有看到这个插件的就不要浪费时间了,这么不成熟的插件头一次见到, 白白浪费了10分钟。
最近看了很多关于存储的资料, 深raid, fc, sas, nas 一大堆名词扑面而来。 看的时候就一直在想一个问题, 如何能保证数据的安全性呢? 可以用raid, 可万一raid卡坏了怎么办? 那就用双机热备份, 可万一这个机房着火了怎么办, 那就只有在一个远离这个机房的地方再保存一个备份才能保证数据安全了。 大公司有这么做的, 北京政府甚至在昌平专门建有冗灾数据中心, 但这对广大的中小厂商来说有成本太高之嫌。这应该就是一个新的机会,IT业发展到现在需要有专业的第三方的廉价的数据存储冗灾公司。
下面设想一下这样的公司的实现细节,他应该有如下特点
这些应该都没什么不可逾越的技术难度。 微软和google现在都在搞网络硬盘, 应该就有这个意思。设想的这种第三方数据冗灾服务应该不远了,没准早有了,只是我还不知道。
昨天深夜开始安装Subversion,折腾了很久,终于搞定。 把过程写出来与大家分享,整个安装过程主要参考了 http://www.jlchannel.com/blog/?p=104 和 http://www.newbooks.com.cn/info/52691.html。
安装环境为
内核:Linux version 2.6.9-34.ELsmp
操作系统:Red Hat Enterprise Linux AS release 4 (Nahant Update 3)
Web Server: Apache 2.0 ( Web server必须是Apache 2.0以上,Subversion数据库才能通过http协议去访问)
后记:
要注意的还有如下几点:
